Sensor-Independent Illumination Estimation for DNN Models
Mahmoud Afifi1 and Michael S. Brown1,2
1York University, 2Samsung Research
Abstract
While modern deep neural networks (DNNs) achieve state-of-the-art results
for illuminant estimation, it is currently necessary to train a separate DNN for each type of camera sensor.
This means when a camera manufacturer uses a new sensor, it is necessary to re-train an existing DNN model with training images captured by the new sensor.
This paper addresses this problem by introducing a novel sensor-independent illuminant estimation framework. Our method learns a sensor-independent working space
that can be used to canonicalize the RGB values of any arbitrary camera sensor. Our learned space retains the linear property of the original sensor raw-RGB space and allows
unseen camera sensors to be used on a single DNN model trained on this working space. We demonstrate the effectiveness of this approach on several different camera sensors
and show it provides performance on par with state-of-the-art methods that were trained per sensor.
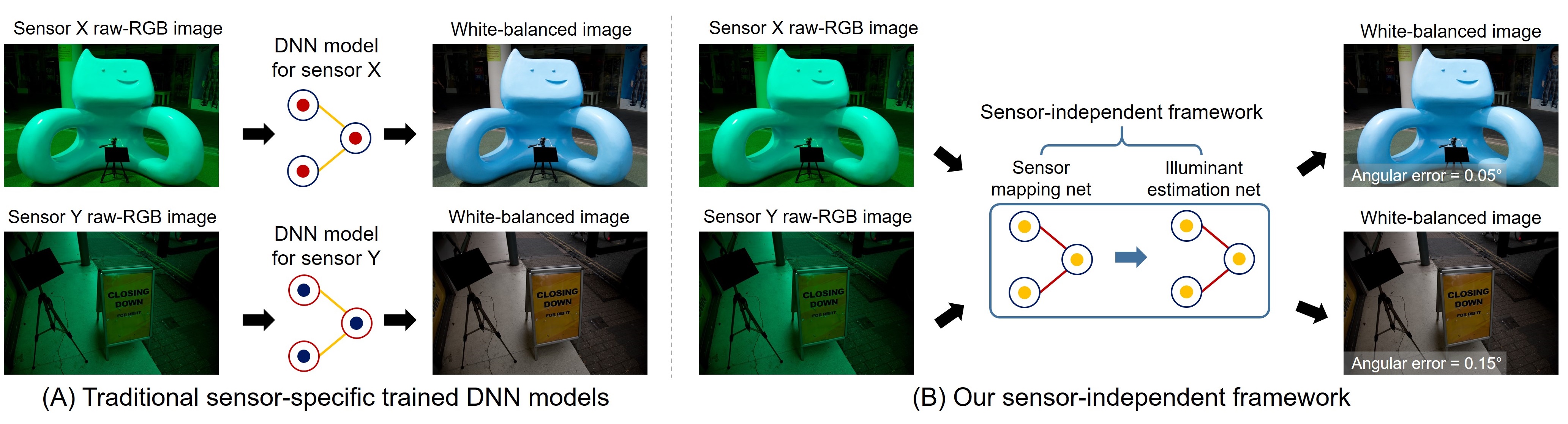
Solution
We introduce a sensor-independent learning framework for illuminant estimation.
The idea is similar to the color space conversion process applied onboard cameras that maps the sensor-specific RGB values to a perceptual-based color space — namely, CIE XYZ.
The color space conversion process estimates a color space transform (CST) matrix to map white-balanced sensor-specific raw-RGB images to CIE XYZ.
This process is applied onboard cameras after the illuminant estimation and white-balance step, and relies on the estimated scene illuminant to compute the CST matrix.
Our solution, however, is to learn a new space that is used before the illuminant estimation step.
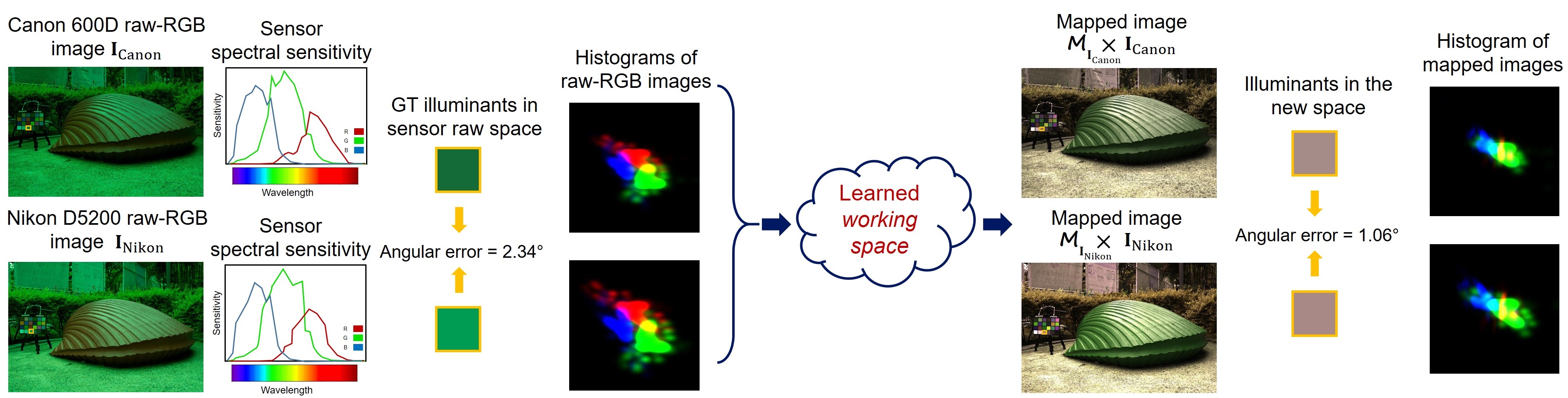
Specifically, we design a novel unsupervised deep learning framework that learns how to map each input image, captured by arbitrary camera sensor, to a non-perceptual sensor-independent working space. Mapping input images to this space, allows us to train our model using training sets captured by different camera sensors achieving good accuracy and generalizing well for unseen camera sensors.
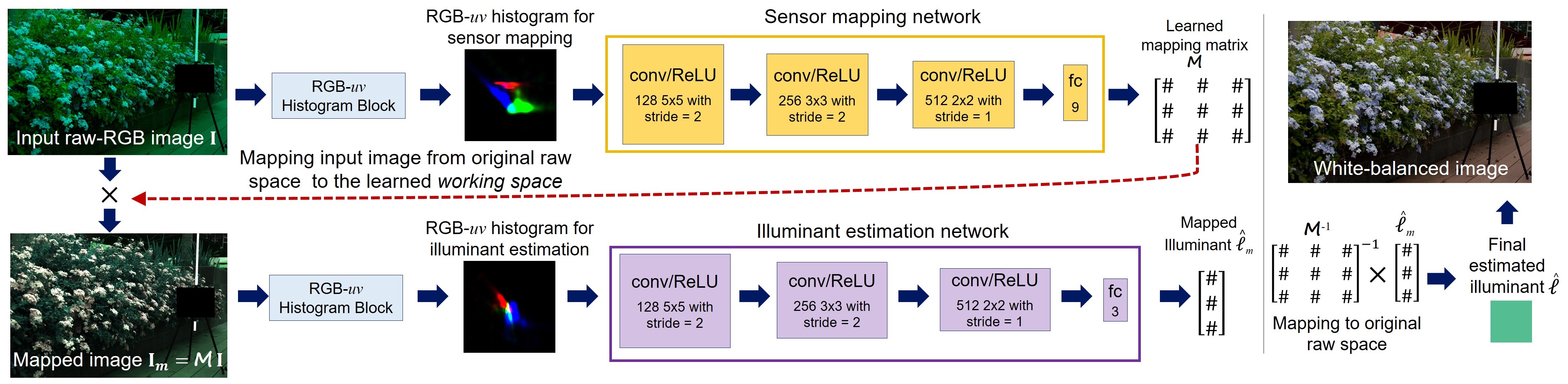
Results
We used the leave-one-out cross-validation scheme to evaluate our method on all cameras of
NUS 8-Camera,
Gehler-Shi,
and Cube+ datasets. We further tested our trained models on Cube+ challenge
and INTEL-TUT dataset. Read our paper for more results.

Angular errors on NUS 8-Camera and
Gehler-Shi datasets. For more information, please read our paper.
| Methods | NUS 8-Camera | Gehler-Shi | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Median | Best 25% | Worst 25% | Mean | Median | Best 25% | Worst 25% | |
| Avg. sensor-independent methods | 4.26 | 3.25 | 0.99 | 9.43 | 5.10 | 4.03 | 1.91 | 10.77 |
| Avg. sensor-dependent methods | 2.40 | 1.64 | 0.50 | 5.75 | 2.62 | 1.75 | 0.50 | 5.95 |
| Ours | 2.05 | 1.50 | 0.52 | 4.48 | 2.77 | 1.93 | 0.55 | 6.53 |
Angular errors on Cube/Cube+ datasets. For more information, please read our paper.
| Methods | Cube | Cube+ | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Median | Best 25% | Worst 25% | Mean | Median | Best 25% | Worst 25% | |
| Avg. sensor-independent methods | 3.57 | 2.47 | 0.64 | 8.30 | 4.98 | 3.32 | 0.82 | 11.77 |
| Avg. sensor-dependent methods | 1.54 | 0.92 | 0.26 | 3.85 | 2.04 | 1.02 | 0.25 | 5.58 |
| Ours | 1.98 | 1.36 | 0.40 | 4.64 | 2.14 | 1.44 | 0.44 | 5.06 |
Files
| |
|
|
|
| Paper | Supplementary Materials | PPSX | PPTX | Code |
BibTeX
@inproceedings{Afifi2019Sensor,
booktitle = {British Machine Vision Conference (BMVC)},
title = {Sensor-Independent Illumination Estimation for DNN Models},
author = {Afifi, Mahmoud and Brown, Michael S.},
year = {2019},
}